Have you ever wondered how decision trees work and how they can be applied in real-world scenarios? Decision trees are powerful tools used across various fields for decision-making, data analysis, and predictive modeling. They offer a clear and visual representation of decisions and their potential outcomes, making them invaluable in numerous applications. This comprehensive guide will walk you through several decision tree examples with solutions, providing you with a deeper understanding of their utility and how you can implement them effectively.
Decision trees are not only useful for data scientists and analysts; they also have practical applications in business, healthcare, finance, and many other domains. Whether you're trying to predict customer behavior, diagnose a medical condition, or assess financial risks, decision trees can offer insightful solutions. By breaking down complex decisions into manageable parts, decision trees help simplify the decision-making process, enabling more informed and accurate outcomes.
In this article, we'll delve into a variety of decision tree examples with solutions, showcasing their versatility and practicality. We'll explore how decision trees can be used to solve classification problems, regression tasks, and even in strategic business planning. With detailed explanations, step-by-step solutions, and illustrative examples, you'll gain a comprehensive understanding of how to harness the power of decision trees in your own work. Let's dive in and uncover the potential of decision trees through these engaging examples.
Table of Contents
- Understanding Decision Trees
- The Structure of a Decision Tree
- How Decision Trees Are Built
- Decision Tree Algorithms
- Classification Trees
- Regression Trees
- Decision Tree in Business Strategy
- Healthcare Applications
- Financial Risk Assessment
- Decision Tree Software Tools
- Advantages and Disadvantages
- Real-World Case Studies
- Common Challenges and Solutions
- Future Trends in Decision Trees
- FAQs
- Conclusion
Understanding Decision Trees
Decision trees are a type of model used for decision-making, which visually maps out decisions and their possible consequences. They are a fundamental component of machine learning, especially in classification and regression tasks. A decision tree is structured like a flowchart, where each internal node represents a test on an attribute, each branch denotes the outcome of the test, and each leaf node signifies a class label or decision outcome.
The primary objective of a decision tree is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. Decision trees are highly interpretable and easy to understand, making them a preferred choice for many applications where interpretability is crucial. They are non-parametric models, meaning they do not assume any distribution for the input data, which enhances their flexibility.
In its simplest form, a decision tree can be used to represent a series of binary decisions leading to a final outcome. Each node in the tree acts as a decision point, guiding the flow based on the available data attributes. This structure allows decision trees to handle both numerical and categorical data effectively. As we progress through this article, we'll explore various examples to see how decision trees are applied in different contexts.
The Structure of a Decision Tree
A decision tree consists of several key components that work together to facilitate decision-making. Understanding these components is essential for grasping how decision trees function:
Root Node
The root node is the topmost node of the decision tree. It represents the entire dataset, which is divided into subsets based on an attribute. The root node is where the decision-making process begins, and it branches out to subsequent nodes.
Decision Nodes
Decision nodes are the internal nodes that signify a test on a specific attribute. These nodes help split the data into smaller subsets, each corresponding to a different value or range of the attribute. The decision nodes guide the decision-making process by directing the flow based on the test outcomes.
Leaf Nodes
Leaf nodes, also known as terminal nodes, represent the final decision or classification outcome. These nodes do not split further, and each leaf node is assigned a class label or value based on the path taken from the root node.
Branches
Branches connect the nodes in a decision tree, representing the outcome of a test at a decision node. Each branch corresponds to a different value or range of the attribute being tested, guiding the flow to the appropriate child node.
Splitting
Splitting is the process of dividing a node into two or more sub-nodes based on a decision criterion. The goal is to create homogeneous sub-nodes, where the target variable is more similar within each subset. Splitting continues recursively until a stopping condition is met, such as reaching a maximum tree depth or achieving minimal impurity.
By understanding the structure of a decision tree, you can better appreciate how it functions as a decision-making tool. In the following sections, we'll explore how decision trees are constructed and the algorithms used to create them.
How Decision Trees Are Built
Building a decision tree involves several steps, which transform raw data into a structured model that can make predictions or classifications. Here's an overview of the process:
Data Collection and Preprocessing
The first step in building a decision tree is to gather relevant data. This data should contain the features or attributes that will be used to make decisions, as well as the target variable, which is the outcome you want to predict. Data preprocessing involves cleaning and preparing the data, handling missing values, and encoding categorical variables if necessary.
Choosing the Splitting Criteria
Splitting criteria are essential for determining how the data is divided at each node. Common criteria include Gini impurity, entropy, and information gain. These metrics evaluate the homogeneity of the data within sub-nodes, guiding the selection of the best attribute for splitting.
Recursive Splitting
Once the splitting criterion is chosen, the algorithm recursively splits the data at each node to create sub-nodes. This process continues until a stopping condition is met, such as reaching a predefined maximum depth, achieving a minimum impurity, or having a minimal number of samples in a node.
Pruning the Tree
Pruning is an essential step to prevent overfitting, which occurs when the decision tree becomes too complex and captures noise in the data. Pruning involves removing branches that have little impact on the overall prediction accuracy. Techniques such as cost complexity pruning and reduced error pruning are commonly used.
Evaluating the Model
After constructing the decision tree, the model is evaluated using a test dataset to assess its accuracy and effectiveness. Metrics such as precision, recall, F1 score, and the confusion matrix are used to evaluate the performance of the decision tree.
By following these steps, you can build a robust decision tree model that provides valuable insights and predictive capabilities. In the next section, we'll explore the different algorithms used to create decision trees.
Decision Tree Algorithms
Several algorithms are used to build decision trees, each with its own approach to splitting data and constructing the tree. Here are some of the most popular decision tree algorithms:
ID3 (Iterative Dichotomiser 3)
ID3 is one of the earliest decision tree algorithms, developed by Ross Quinlan. It uses information gain as a splitting criterion, selecting the attribute that provides the highest information gain to split the data. ID3 is primarily used for categorical data.
C4.5
C4.5 is an extension of the ID3 algorithm, also developed by Ross Quinlan. It improves upon ID3 by handling both categorical and continuous attributes and using the gain ratio as a splitting criterion. C4.5 also includes mechanisms for pruning and dealing with missing values.
CART (Classification and Regression Trees)
CART is a versatile algorithm that can be used for both classification and regression tasks. It uses Gini impurity as a splitting criterion for classification and mean squared error for regression. CART produces binary trees, where each internal node has two children.
CHAID (Chi-squared Automatic Interaction Detector)
CHAID is a decision tree algorithm that uses the chi-squared test to determine the best split. It is suitable for categorical data and is often used in marketing and social science research for segmenting and profiling target audiences.
Random Forest
Random forest is an ensemble learning technique that constructs multiple decision trees and combines their outputs to improve accuracy and robustness. It uses a random subset of features for each tree, reducing overfitting and increasing generalization.
These algorithms provide different approaches to building decision trees, each with its strengths and weaknesses. By understanding these algorithms, you can choose the one that best fits your specific problem and data characteristics. In the following sections, we'll explore practical examples of decision trees in various domains.
Classification Trees
Classification trees are a type of decision tree used to categorize data into discrete classes. They are widely used in machine learning for tasks such as spam detection, image recognition, and customer segmentation. Let's explore a practical example of a classification tree:
Example: Classifying Iris Flower Species
The Iris dataset is a classic example used to demonstrate classification tasks. It contains measurements of iris flowers from three different species: Iris setosa, Iris versicolor, and Iris virginica. The dataset includes features such as sepal length, sepal width, petal length, and petal width.
To build a classification tree, we start by splitting the dataset into a training set and a test set. Using the CART algorithm, we construct a decision tree that predicts the species of an iris flower based on its features. The tree splits the data based on the most informative features, leading to a series of decision nodes that classify the flowers into one of the three species.
Solution
The resulting decision tree provides a visual representation of the classification process. For example, the root node may split the data based on petal length, with further splits based on sepal width and petal width. Each leaf node represents a predicted species label, allowing us to classify new iris flowers based on their measurements.
Classification trees are powerful tools for understanding complex patterns in data and making accurate predictions. They provide a clear and interpretable model that can be easily communicated to stakeholders. In the next section, we'll explore regression trees and their applications.
Regression Trees
Regression trees are used to predict continuous numerical values rather than discrete classes. They are commonly applied in tasks such as sales forecasting, real estate valuation, and resource allocation. Let's explore an example of a regression tree:
Example: Predicting Housing Prices
Suppose we have a dataset containing information about houses, including features such as square footage, number of bedrooms, location, and age of the property. Our goal is to predict the sale price of a house based on these features.
Using the CART algorithm, we construct a regression tree that models the relationship between the features and the target variable, which is the sale price. The tree splits the data based on the most influential features, creating a series of decision nodes that provide predictions for the sale price.
Solution
The resulting regression tree provides a visual representation of the prediction process. For example, the root node may split the data based on square footage, with further splits based on location and number of bedrooms. Each leaf node represents a predicted sale price, allowing us to estimate the price of new houses based on their features.
Regression trees offer a straightforward and interpretable approach to modeling continuous data. They provide valuable insights into the relationships between features and target variables, enabling more informed decision-making. In the following sections, we'll explore how decision trees are applied in business strategy and other domains.
Decision Tree in Business Strategy
Decision trees play a crucial role in strategic business planning, helping organizations make informed decisions by visualizing potential outcomes and their associated risks. They are used in various business contexts, such as market analysis, resource allocation, and risk management. Let's explore an example of a decision tree in business strategy:
Example: Expanding into a New Market
A company is considering expanding its operations into a new geographical market. The decision involves several factors, including market size, competition, regulatory environment, and potential revenue. A decision tree can help visualize the decision-making process and assess the potential outcomes.
Solution
The decision tree begins with the root node, representing the decision to expand into the new market. It branches out into different scenarios based on factors such as market size and competition. Each decision node represents a choice, such as entering the market, delaying entry, or opting for a partnership. The leaf nodes represent the potential outcomes, such as increased revenue, market share growth, or financial loss.
By analyzing the decision tree, the company can evaluate the risks and benefits of each option, making a more informed decision about market expansion. Decision trees provide a clear and structured approach to strategic planning, enabling organizations to navigate complex decisions with confidence. In the next section, we'll explore the application of decision trees in healthcare.
Healthcare Applications
Decision trees are widely used in healthcare for diagnosing medical conditions, predicting patient outcomes, and optimizing treatment plans. They provide a transparent and interpretable model that aids healthcare professionals in making evidence-based decisions. Let's explore an example of a decision tree in healthcare:
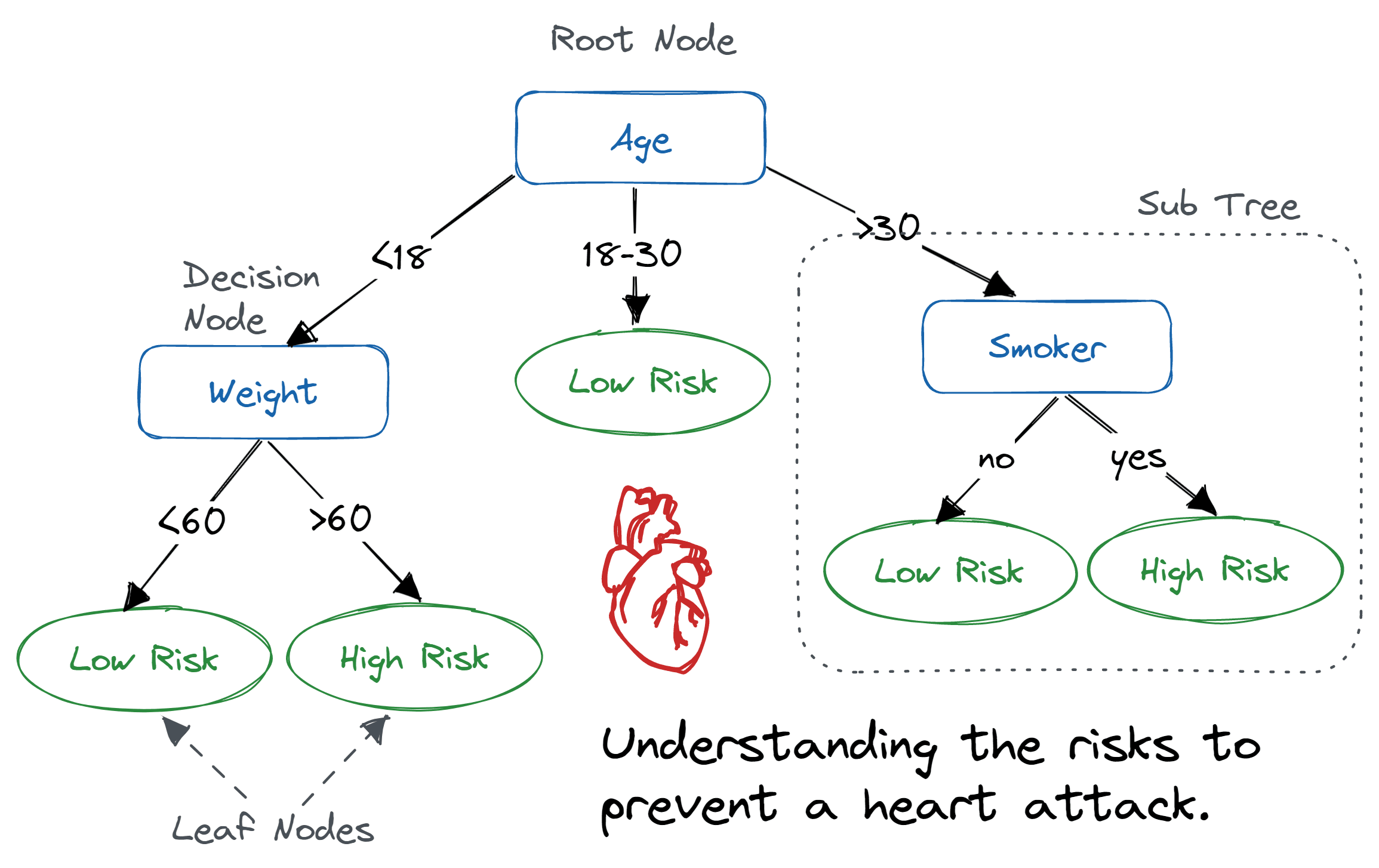
Example: Diagnosing Heart Disease
A healthcare provider has a dataset containing patient information, including age, gender, cholesterol levels, blood pressure, and other risk factors. The goal is to develop a decision tree model that predicts the likelihood of heart disease based on these features.
Solution
Using a classification tree algorithm, the decision tree is constructed to classify patients into two categories: those with heart disease and those without. The tree splits the data based on the most informative features, such as cholesterol levels and blood pressure, leading to decision nodes that predict the presence of heart disease.
The resulting decision tree provides a visual representation of the diagnostic process, allowing healthcare professionals to assess the risk factors and make informed decisions about patient care. Decision trees offer a valuable tool for early diagnosis and personalized treatment planning, improving patient outcomes and quality of care. In the following sections, we'll explore the application of decision trees in financial risk assessment.
Financial Risk Assessment
Decision trees are used in finance to assess risks, make investment decisions, and optimize portfolio management. They provide a structured approach to analyzing potential outcomes and their associated probabilities, enabling more informed financial decision-making. Let's explore an example of a decision tree in financial risk assessment:
Example: Evaluating Investment Options
An investment firm is considering several investment options, each with different risk levels, expected returns, and market conditions. A decision tree can help visualize the decision-making process and evaluate the potential outcomes.
Solution
The decision tree begins with the root node, representing the decision to invest in a particular option. It branches out into different scenarios based on factors such as market volatility and economic indicators. Each decision node represents a choice, such as investing, holding, or diversifying the portfolio. The leaf nodes represent the potential outcomes, such as profit, loss, or breakeven.
By analyzing the decision tree, the investment firm can assess the risks and rewards of each option, making a more informed decision about portfolio management. Decision trees provide a clear and visual representation of financial risks, enabling organizations to navigate complex investment decisions with confidence. In the next section, we'll explore the tools and software used to create decision trees.
Decision Tree Software Tools
Several software tools and platforms are available for creating and analyzing decision trees. These tools offer user-friendly interfaces, advanced algorithms, and visualization capabilities, making it easier to build, evaluate, and interpret decision trees. Here are some popular decision tree software tools:
R and Python Libraries
R and Python are popular programming languages used for data analysis and machine learning. Libraries such as 'rpart' in R and 'scikit-learn' in Python offer robust implementations of decision tree algorithms, allowing users to build and visualize decision trees with ease.
RapidMiner
RapidMiner is a data science platform that provides a visual workflow for building decision trees. It offers a wide range of machine learning algorithms, including decision trees, and supports data preprocessing, modeling, and evaluation.
Microsoft Excel
Microsoft Excel offers add-ins and plugins for creating decision trees, such as the 'Decision Tree' tool in the 'Solver Add-in.' These tools provide a simple and intuitive way to build decision trees directly within Excel spreadsheets.
IBM SPSS Modeler
IBM SPSS Modeler is a data mining and predictive analytics platform that includes decision tree algorithms. It offers a graphical interface for building decision trees and supports integration with other IBM analytics tools.
KNIME
KNIME is an open-source data analytics platform that provides a visual workflow for building decision trees. It offers a wide range of data processing, modeling, and visualization tools, making it suitable for various data science tasks.
These software tools provide powerful solutions for creating and analyzing decision trees, enabling users to leverage the full potential of decision tree models. In the following sections, we'll explore the advantages and disadvantages of decision trees.
Advantages and Disadvantages
Decision trees offer several advantages, making them a popular choice for decision-making and predictive modeling. However, they also have some limitations that should be considered. Let's explore the advantages and disadvantages of decision trees:
Advantages
- Interpretable and Transparent: Decision trees provide a clear and visual representation of the decision-making process, making them easy to interpret and understand.
- Handles Both Categorical and Numerical Data: Decision trees can work with both types of data, making them versatile for different applications.
- Non-Parametric: Decision trees do not assume any distribution for the input data, allowing them to handle complex and non-linear relationships.
- Feature Selection: Decision trees automatically perform feature selection by choosing the most informative attributes for splitting.
- Robust to Outliers: Decision trees are less sensitive to outliers compared to other models, as they focus on splitting data based on attribute values.
Disadvantages
- Overfitting: Decision trees can become too complex and capture noise in the data, leading to overfitting. Pruning techniques are necessary to mitigate this issue.
- Instability: Small changes in the data can lead to significant changes in the structure of the decision tree, affecting its stability.
- Bias Towards Dominant Classes: Decision trees can be biased towards classes that dominate the dataset, affecting the accuracy of minority class predictions.
- Limited Expressiveness: Decision trees may struggle to capture complex relationships that require interactions between multiple attributes.
By understanding the advantages and disadvantages of decision trees, you can make informed decisions about their suitability for your specific problem and data characteristics. In the following sections, we'll explore real-world case studies that demonstrate the application of decision trees.
Real-World Case Studies
Decision trees have been successfully applied in various real-world scenarios, providing valuable insights and predictive capabilities. Let's explore some case studies that demonstrate the application of decision trees:
Case Study 1: Predicting Customer Churn
A telecommunications company used decision trees to predict customer churn, enabling them to identify at-risk customers and implement retention strategies. By analyzing customer data, such as call patterns, billing information, and customer demographics, the decision tree model identified key factors contributing to churn. This information allowed the company to tailor their marketing efforts and reduce customer attrition.
Case Study 2: Diagnosing Diabetes
A healthcare provider utilized decision trees to improve the diagnosis of diabetes. By analyzing patient data, such as age, body mass index, blood pressure, and glucose levels, the decision tree model predicted the likelihood of diabetes with high accuracy. This helped healthcare professionals identify high-risk patients and implement preventive measures, improving patient outcomes and reducing healthcare costs.
Case Study 3: Fraud Detection in Banking
A bank implemented decision trees to detect fraudulent transactions in real-time. By analyzing transaction data, such as transaction amount, location, and time, the decision tree model identified patterns indicative of fraudulent activity. This enabled the bank to flag suspicious transactions and take preventive actions, reducing financial losses and enhancing security measures.
Case Study 4: Optimizing Supply Chain Management
A manufacturing company used decision trees to optimize their supply chain management. By analyzing production data, demand forecasts, and inventory levels, the decision tree model identified optimal production schedules and inventory policies. This improved the company's operational efficiency, reduced costs, and enhanced customer satisfaction.
These case studies highlight the versatility and practicality of decision trees in solving real-world problems. By leveraging decision trees, organizations can make data-driven decisions, improve efficiency, and achieve better outcomes. In the following sections, we'll explore common challenges and solutions associated with decision trees.
Common Challenges and Solutions
While decision trees offer powerful solutions for decision-making and predictive modeling, they also present some challenges that need to be addressed. Let's explore common challenges associated with decision trees and potential solutions:
Challenge 1: Overfitting
Overfitting occurs when a decision tree becomes too complex and captures noise in the data, leading to poor generalization on new data. To address overfitting, consider the following solutions:
- Pruning: Apply pruning techniques, such as cost complexity pruning or reduced error pruning, to remove unnecessary branches and simplify the tree.
- Use Ensemble Methods: Consider using ensemble methods, such as random forests or boosting, which combine multiple decision trees to improve accuracy and robustness.
- Limit Tree Depth: Set a maximum depth for the decision tree to prevent it from growing too deep and capturing noise.
Challenge 2: Data Imbalance
Data imbalance occurs when one class dominates the dataset, leading to biased predictions. To address data imbalance, consider the following solutions:
- Resampling Techniques: Use resampling techniques, such as oversampling the minority class or undersampling the majority class, to balance the dataset.
- Use Class Weights: Assign different weights to classes based on their frequency to give more importance to minority classes during training.
- Use Ensemble Methods: Consider using ensemble methods that are less sensitive to data imbalance, such as random forests or boosting.
Challenge 3: Interpretability
While decision trees are generally interpretable, complex trees can become difficult to understand. To improve interpretability, consider the following solutions:
- Visualize the Tree: Use visualization tools to create clear and concise representations of the decision tree, highlighting important features and decision nodes.
- Feature Importance: Analyze feature importance scores to identify the most influential features and simplify the decision-making process.
- Limit Tree Complexity: Use pruning techniques to simplify the tree and focus on the most relevant decision paths.
By addressing these challenges, you can enhance the performance and reliability of decision tree models, ensuring they provide valuable insights and predictions. In the following sections, we'll explore future trends and developments in decision trees.
Future Trends in Decision Trees
Decision trees continue to evolve, with ongoing research and development driving new trends and advancements. Here are some future trends and developments in decision trees:
Trend 1: Explainable AI
As the demand for explainable AI increases, decision trees are expected to play a more significant role in providing interpretable models. Researchers are exploring new techniques to enhance the transparency and interpretability of decision tree models, making them more accessible to non-experts.
Trend 2: Integration with Deep Learning
Integrating decision trees with deep learning models is an emerging trend aimed at combining the interpretability of decision trees with the predictive power of deep learning. Hybrid models that leverage the strengths of both approaches are being developed for complex tasks where interpretability is crucial.
Trend 3: Efficient Tree Construction
Researchers are exploring new algorithms and techniques to improve the efficiency of decision tree construction, especially for large datasets. Techniques such as distributed decision tree algorithms and parallel processing are being developed to enhance scalability and reduce computation time.
Trend 4: Automated Machine Learning (AutoML)
AutoML platforms are incorporating decision trees as part of their automated machine learning pipelines. These platforms aim to simplify the process of building and optimizing decision tree models, making them more accessible to users with limited technical expertise.
These trends highlight the ongoing advancements in decision trees and their potential to address new challenges and opportunities in the field of data science. In the following section, we'll address some frequently asked questions about decision trees.
FAQs
1. What is a decision tree?
A decision tree is a model used for decision-making and predictive modeling, representing decisions and their possible consequences in a tree-like structure. It consists of nodes that represent tests on attributes, branches that indicate outcomes, and leaf nodes that signify decision outcomes.
2. How are decision trees used in machine learning?
Decision trees are used in machine learning for classification and regression tasks. They learn decision rules from data features to make predictions about target variables. Decision trees are interpretable models that provide insights into the decision-making process.
3. What are the advantages of decision trees?
Decision trees offer several advantages, including interpretability, versatility in handling categorical and numerical data, non-parametric nature, feature selection, and robustness to outliers. They provide a clear and visual representation of the decision-making process.
4. What are the limitations of decision trees?
Decision trees have limitations, such as overfitting, instability, bias towards dominant classes, and limited expressiveness for complex relationships. Pruning techniques, ensemble methods, and other approaches can address these limitations.
5. How can decision trees be used in business strategy?
Decision trees are used in business strategy for market analysis, resource allocation, and risk management. They help visualize potential outcomes, assess risks, and make informed decisions based on data-driven insights.
6. What software tools are available for building decision trees?
Several software tools are available for building decision trees, including R and Python libraries, RapidMiner, Microsoft Excel add-ins, IBM SPSS Modeler, and KNIME. These tools provide user-friendly interfaces and advanced algorithms for creating and analyzing decision trees.
Conclusion
In conclusion, decision trees are powerful tools for decision-making and predictive modeling, offering clear and interpretable models that enhance understanding and insights. Through this comprehensive guide, we've explored various decision tree examples with solutions, showcasing their versatility and applicability across different domains. From classification and regression tasks to strategic business planning and healthcare applications, decision trees provide valuable solutions for complex problems.
By understanding the structure, algorithms, and potential challenges associated with decision trees, you can leverage their full potential in your own work. As the field of data science continues to evolve, decision trees will remain a fundamental component, with ongoing research and development driving new trends and advancements.
We hope this guide has provided you with a deeper understanding of decision tree examples with solutions and inspired you to explore their applications further. Whether you're a data scientist, business professional, or healthcare provider, decision trees offer powerful tools to enhance decision-making and achieve better outcomes.
You Might Also Like
The Chav Look: A Comprehensive ExplorationExploring The Chilling World Of Good Serial Killer Books: A Guide To Captivating Reads
Unveiling The Bright Future Of Sunshine Car Wash: A Comprehensive Guide
Understanding "What Store Is Opened": A Comprehensive Guide
Discovering The Allure Of Love Perfume By Coach: A Comprehensive Guide
Article Recommendations
- Opal Engagement Ring
- Tooth Lady China Concubine
- Smallest Trees In The World
- Cons For Electric Cars
- Are Egg Cartons Recyclable
- Feeling Unappreciated
- Adhd And Gaming
- Ubuntu Install Deb File Command Line
- What Is Corbels
- How Old Is Hawks Mom 7ds